D3 js 笔记02
常用的操作:选择,插入,删除,前面已经讲了选择元素的相关操作,这里还是简单记一下。
元素操作
选择元素
假设有三个元素
1 | <p>test1</p> |
下面的操作都是基于这三个的元素的操作
选择第一个p元素
1 | var p1 = body.sellect("p"); |
全选
1 | var p = body.sellectAll("p"); |
选择指定元素
- 通过元素id属性
1 | <p> id="id_2">Test 2</p> |
然后使用下面的代码来改变第二个元素的颜色
1 | var p2 = body.select("#id_2"); |
- 通过元素class属性
假设有如下内容,把这个内容改一下:
1 | <p class="c1" id="id_1">Apple</p> |
可以使用下面的方法:
1 | var p = body.selectAll(".c1"); |
备注:关于select()和selectAll()的参数,其实是符合CSS选择器的条件的,即用#表示id,用.表示class.这样可以把前两个内容设置成蓝色。
插入
和Python很像,有insert()以及append()方法:
1 | append(): # 在选择集末尾插入元素 |
例子:
1 | body.append("p").text("append p element"); # 在最后插入一个<p>元素,并且设置文本内容 |
结果如下:
1 | Apple |
删除
这个简单,直接使用remove()即可,对于上面的代码:
1 | var p = body.select("#id_1"); |
简单图表
简单介绍一下图表,但是的先明白几个常见的术语:
要画图,必须要在一个用来画图的东西,通常我们用画布来画图,常见的画布又两种:SVG和Canvas。
- SVG
SVG是指可缩放的矢量图形,主要用来描述二维矢量图形,定义图形也很简单,使用xml来定义图形。由于是用xml来定义图形,所以每个元素都可以添加JavaScript事件处理器。
- Canvas
Canvas是通过JavaScript来绘制2D图形
**注意:**这里需要说明一下,D3提供的很多画图的函数都是SVG图形生成器,所以建议在学习D3.js的时候使用SVG画布,添加一个SVG也很简单:
1 | var width = 300; //画布的宽度 |
下面就可以在这个svg上画各种图了,先上源码:
1 | <html> |
解释一下,<rect>为矩形,它有四个属性:
1 | x:矩形左上角的 x 坐标 |
其中x轴正方向为水平向右,y轴正方向为垂直向下:
1 | var dataSet = [250, 210, 170, 130, 90]; |
用来存储几个长方形的长度,即width属性值,添加和dataSet数量相等的矩形,所使用的代码是:
1 | svg.selectAll("rect") |
这段代码先记住,可以添加足够多的元素,后面细讲机制,然后就是前面讲过的给元素附属性值了,依次给每个举行设置那四个属性的值,dataSet里面的元素设置成举行的width属性值,最后设置一下颜色,效果如下: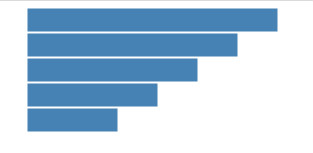
比例尺
上面的设置矩形的长度用的是一个数组,里面的值直接设置成了矩形的像素长度,但是这样比较死,有可能太大也有可能太小,所以使用比例尺是个不错的注意,只要设置一种放缩关系,只用设定上下限,中间的值会自动放缩会很方便。
简单来说就是一个函数x->y这样的一种映射关系,x为定义域,y为值域。
线性比例尺
这种比例尺比较常用,也比较简单,使用上只用设定上下限即可:
1 | var dataSet = [1.2, 2.3, 0.9, 1.5, 3.3]; |
d3.scale.linear()返回线性比例尺,也可以当函数使用。
离散比例尺
有时候需要的并不一定是线性连续的映射关系,可能是把某一批转化成另一类元素,例如:
1 | var index = [0, 1, 2, 3, 4]; |
需要把对应的序号映射到颜色上去,用序数比例尺就更合适:
1 | var ordinal = d3.scale.ordinal() |
所以上面讲的柱形图,我们可以利用比例尺改写一下:
1 | var rectHeight = 25; //每个矩形所占的像素高度(包括空白) |