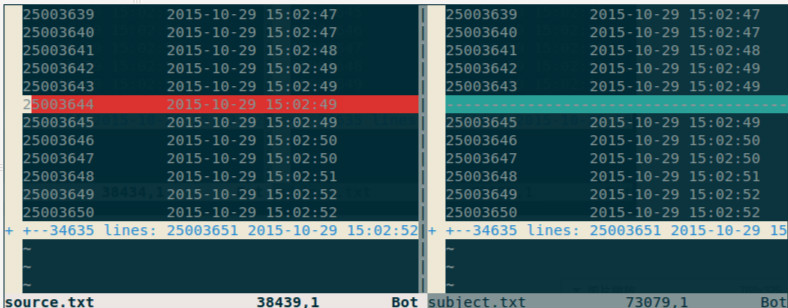
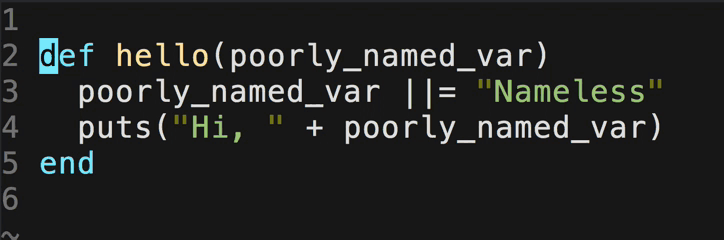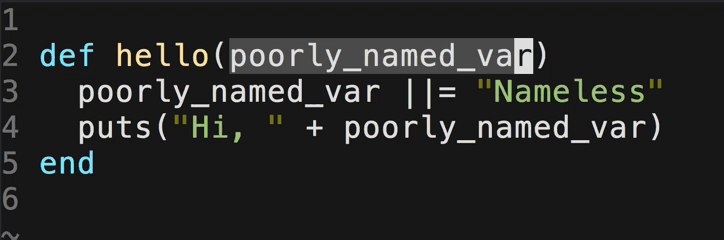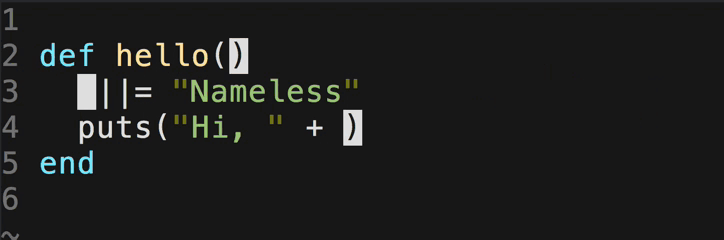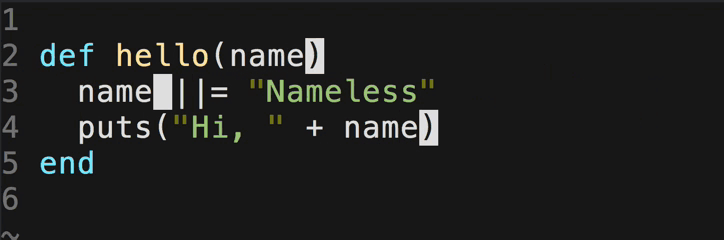
sudo -uuser_name /home/dev/hive-0.12.0/bin/hive -database dw_subject -e "select idid,create_time from table_name where (create_time>='2015-10-29 00:00:00' and create_time<='2015-10-29 23:59:59') order by idid;" > subject.txt
ssh zhang.san@redirector.machine.com Enter PASSCODE:"输入密码处" Last login: Tue Oct 27 19:16:47 2015 from 10.86.108.97 [zhang.san@redirector.machine.com ~]$ ls 1.txt
# deb cdrom:[Ubuntu-Kylin 14.04.1 LTS _Trusty Tahr_ - Release amd64 (20140722.1)]/ trusty main multiverse restricted universe
# See http://help.ubuntu.com/community/UpgradeNotes for how to upgrade to # newer versions of the distribution. deb http://cn.archive.ubuntu.com/ubuntu/ trusty main restricted deb-src http://cn.archive.ubuntu.com/ubuntu/ trusty main restricted
## Major bug fix updates produced after the final release of the ## distribution. deb http://cn.archive.ubuntu.com/ubuntu/ trusty-updates main restricted deb-src http://cn.archive.ubuntu.com/ubuntu/ trusty-updates main restricted
## N.B. software from this repository is ENTIRELY UNSUPPORTED by the Ubuntu ## team. Also, please note that software in universe WILL NOT receive any ## review or updates from the Ubuntu security team. deb http://cn.archive.ubuntu.com/ubuntu/ trusty universe deb-src http://cn.archive.ubuntu.com/ubuntu/ trusty universe deb http://cn.archive.ubuntu.com/ubuntu/ trusty-updates universe deb-src http://cn.archive.ubuntu.com/ubuntu/ trusty-updates universe
## N.B. software from this repository is ENTIRELY UNSUPPORTED by the Ubuntu ## team, and may not be under a free licence. Please satisfy yourself as to ## your rights to use the software. Also, please note that software in ## multiverse WILL NOT receive any review or updates from the Ubuntu ## security team. deb http://cn.archive.ubuntu.com/ubuntu/ trusty multiverse deb-src http://cn.archive.ubuntu.com/ubuntu/ trusty multiverse deb http://cn.archive.ubuntu.com/ubuntu/ trusty-updates multiverse deb-src http://cn.archive.ubuntu.com/ubuntu/ trusty-updates multiverse
## N.B. software from this repository may not have been tested as ## extensively as that contained in the main release, although it includes ## newer versions of some applications which may provide useful features. ## Also, please note that software in backports WILL NOT receive any review ## or updates from the Ubuntu security team. deb http://cn.archive.ubuntu.com/ubuntu/ trusty-backports main restricted universe multiverse deb-src http://cn.archive.ubuntu.com/ubuntu/ trusty-backports main restricted universe multiverse
deb http://security.ubuntu.com/ubuntu trusty-security main restricted deb-src http://security.ubuntu.com/ubuntu trusty-security main restricted deb http://security.ubuntu.com/ubuntu trusty-security universe deb-src http://security.ubuntu.com/ubuntu trusty-security universe deb http://security.ubuntu.com/ubuntu trusty-security multiverse deb-src http://security.ubuntu.com/ubuntu trusty-security multiverse
## Uncomment the following two lines to add software from Canonical's ## 'partner' repository. ## This software is not part of Ubuntu, but is offered by Canonical and the ## respective vendors as a service to Ubuntu users. # deb http://archive.canonical.com/ubuntu trusty partner # deb-src http://archive.canonical.com/ubuntu trusty partner
## Uncomment the following two lines to add software from Ubuntu's ## 'extras' repository. ## This software is not part of Ubuntu, but is offered by third-party ## developers who want to ship their latest software. # deb http://extras.ubuntu.com/ubuntu trusty main # deb-src http://extras.ubuntu.com/ubuntu trusty main