线上Jstorm调优及问题排查
问题产生
之前有一段时间beta jstorm集群打日志老是把磁盘都占满了,一开始懒得管,每次都是把dump堆栈文件直接删掉了.但是只是缓解了问题,后面磁盘在一段时间之后还是会别打满,后来有空排查了下问题,简单记录一下.
首先关于如何排查线上Jstorm作业问题这个,其实Jstorm UI也提供了线上的界面,可以查看作业执行日志以及dump堆内存,但是想看实时日志的话还是得到对应机器上查看,另外有些时候还得查看Worker日志才能比较好定位问题,这里用一个线上的实际问题来看下一般怎么排查问题.
问题描述
问题是这样的,Jstorm集群的机器最近经常磁盘报警,线上查看发现是Worker生成了很多*.hprof文件.这里简单说下,Jstorm集群的一个具体的Worker进程在发生OOM的时候会生成dump文件,也就是*.hprof文件,具体参数就是我们常说的-XX:+HeapDumpOnOutOfMemoryError.所以如果程序写的有问题某些参数设置的不对,或者数据量太大导致OOM的话,会不停的dump内存生成文件,直到磁盘被耗光.
问题排查
首先既然是磁盘被耗光了,那先看下磁盘上哪个Worker日志文件占用的磁盘空间最多,定位到具体的Worker之后,我们可以看下jvm运行信息:
可以看到Perm区已经100%了,其他几个区使用率很低,FullGC一直在增加,这个时候基本上就可以判断是Perm区的问题了,我们再确认下Worker的启动参数,直接ps -axu | grep 32502即可:
注意下红色标出来的部分-XX:PermSize=33554432 -XX:MaxPermSize=33554432,算一下基本就是32M这么大.方法区一般存的就是类的信息,这说明加载了太多的Class,可以用jmap -histo:live 32502看下,会发现确实有好多xxxClass的实例,说明确实是.最后我还看了对应的代码文件,发现也的确是用到了很多的的包,并且还是写在static代码块做初始化的.所以最后我改了下启动参数,具体为修改storm.yaml文件:
nimbus.childopts: “ -Xms1g -Xmx1g -Xmn500m -XX:PermSize=50m -XX:SurvivorRatio=4 -XX:MaxTenuringThreshold=15 -XX:+UseConcMarkSweepGC -XX:+UseCMSInitiatingOccupancyOnly -XX:CMSInitiatingOccupancyFraction=70 -XX:CMSFullGCsBeforeCompaction=5 -XX:+HeapDumpOnOutOfMemoryError -verbose:gc -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=5 -XX:GCLogFileSize=100M -XX:+UseCMSCompactAtFullCollection -XX:CMSMaxAbortablePrecleanTime=5000 “
**PS:**当然不是说你改了就可以生效了,你需要先把对应的Worker进程干掉,我一般是直接kill <pid>,因为只要不是强制杀掉,Jstorm会在其他节点重启这个Worker,所以不会丢数据啥的,就直接杀掉了,然后是重启Supervisor进程,然后那些新提交的启动的Worker就会用新的参数启动,所有的就这么简单了,完事儿收工睡觉.
总结
其实在使用了这么久的Jstorm后,也想总结一下个人对Jstorm的看法,或者说大一点,对实时计算框架的一点看法,因为我本人也没有用过原生的Storm,所以这两者的框架优缺点我就不展开了.
首先说下Jstorm,也是目前我们采用的流处理框架,目前业务日志实时处理都是用的Jstorm,处理之后的日志会存到ES/Hbase/Redis这几个地方,上层会有应用去实时使用这些数据.因为日志是不可变更数据,所以Jstorm的异步+compent(并发度) 可以很好的提高吞度量而不用去考虑数据的处理顺序而去而外考虑同步态.并且日志数据的要求会低一些,就是允许丢失部分数据,所以在写ES的时候,也是bulk+异步的方式写,也不至于存储过程卡住.
然后要说的是Spark Streaming,这个也是流处理框架,不过之前更多的是被称作Micro Batch框架,现在好像也支持真正意义上的流式处理了,细节就不多说了,没有实际用过.Spark Streaming在部门使用场景主要是为了处理db binlog数据.前面也说了Jstorm是异步的,意思就是不同的bolt之间异步,同一bolt不同task之间也是异步,但是有一些数据处理场景需要考虑到处理顺序以及同步,如果都是异步处理,那么数据的最终顺序可能会和读取的顺序不一致,所以这个时候就需要采用Async+Sync结合的方式处理.对应Spark Streaming来说就是batch与batch之前同步,batch内部job之间,task之间异步.
这样的好处也比较明显,batch之间类似于有一层屏障来控制顺序,但是batch内部的task并发处理数据,吞吐量也不会受同步影响太高.缺点也比较哦明显,需要等待前面的batch完成,所以latency必定比不上真正的流式处理框架Jstorm.
最后要说的一个是Flink,最初开始了解这个东西是在2016年,所以Flink诞生的时间最晚,因此在设计上也更加的先进(如果不是那也就没有必要重复设计).这个东西目前部门内部没有用,但是公司是主推新的作业尽量用Flink来开发.后面也打算把计算全部迁移到Flink,不过工程量可能有些大.就我调研和使用场景来说.这个东西确实要比Jstorm好,说几个我个人的感觉:
- Flink支持Scala开发,目前Jstorm还是用Java开发,做过数据开发的人就应该知道,Scala在数据处理方面确实要比Java写起来开发效率高很多,Java其优势还是在Web后端这块.
- 调试.这个开发过你就知道了,可能当初
Jstorm的设计人员并没有考虑到这个问题,虽然Jstorm也可以在本地调试,但是需要你写不一样的代码;而Flink以及Spark Streaming这两者代码基本不需要怎么改就可以在本地调试,开发上更人性化. - 设计理念,毕竟是后出来的,肯定设计的初衷也是为了解决当前框架无法解决,或者说无法优雅解决的问题.所以会吸收精华部分,摒弃糟粕,设计理念也会更加先进.尤其是一些关键点:吞吐,延迟,反压这些问题.
另外还有个人建议不使用Jstorm的理由,从去年发布Jstorm 2.2/2.4之后,差不多有一年都没有更新了,社区活跃度不高,Issue基本上没人管了.不过有些东西比较有价值的,flue-core,这个东西其实是Storm的一个插件,当让也可以在Jstorm里面用,简单来说就是可以写一个yaml配置文件去定义一个作业,这样就不用再编译提交jar包来启动作业了.那么我们可以定义或者提前编写一些通用的公共bolt组件,做一个平台来开发Jstorm作业,可以做到页面化开发而不用手写Java代码.
最后说一下自己在使用这些大数据的开源组件的一些见解,其实用过很多组件之后会发现,他们之间会有一些共同的设计理念,举个flume的例子: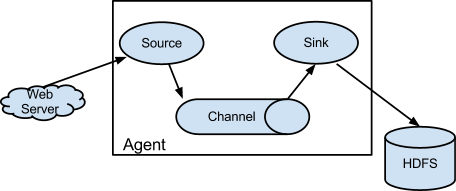
这里有三个比较重要的组件:source,channel,sink.我不知道是不是flume首创的这个,但是从组件的开源时间上来看应该是.很巧的是flink里面也是这么个结构,所以确实可以说这个结构真的是一个优秀的设计思想.尤其是channel这个思想,其实很多的开源组件在设计的时候并没有引入这种设计,比如Canal,所以只能自己去实现具体的数据存储功能,其实这个是不利于推广的,不能开箱即用.正因为Channel的存在,所以source/sink可以实现复用及自由组合,比较灵活,扩展性很强,但是需要有一个Channel支撑,Kafka就是这么个存在,所以Kafka的那几个哥们后来出来创业了,围绕Kafka创建了Confluent,这个里面围绕Kafka创建了各种不同的source/sink,基本涵盖了所有的数据源以及存储源,这种通过一个Channel来缓冲以及解藕不同的逻辑单元,在数据处理领域来说应该是一种非常值得借鉴的思想.在建设基础数据体系或者一个系统的时候,可以多考虑这种结构.