Hive UDF函数开发使用样例
关于UDF的废话也不多讲了,主要讲一下如何开发一个UDF函数以及如何部署到服务器的Hive中使用.
需求背景
有一个Hive表的某个字段是一个collect_set类型,里面是一些数字,类似下面这样:
1 | zhang.san [2,3] |
每个数字都代表着对应的特定的名字,假设配置文件code.properties内容如下:
1 | 0=北京 |
你可以假设这是一个统计一个人去过的城市列表,那么[2,3]就代表这个人去过深圳和香港.当然有些时候数据表里会按照代码的方式来记录,到要用的时候再做一个映射即可,现在有个需求就是,我们要把这些代码换成具体的城市,即一个字典映射,来看看我们如何用UDF函数来解决这个问题.
开发UDF函数
以java代码为例,基于maven构建工程.
新建maven工程
怎么新建Maven工程我这里就不详细讲解了,建好了目录如下:
1 | ➜ hive tree |
备注:src/main目录下的java为代码根目录,resources为资源根目录,test目录为测试根目录,target下的classes目录为.class文件输出路径.
开发代码
分为三个地方:
pom.xml文件
BusinessType.java源码文件
business_no.properties为配置文件,即一个映射字典.
BusinessType.java
代码很简单,如下:
1 | package UDF; |
备注: 函数一定要继承UDF类,并且根据你的业务需求重写里面的evaluate()方法,构造函数从资源根目录读取配置文件,把key-value加载到一个集合中,Hive每次调用的其实是evaluate()函数,对于每个传入的为int型的字段,经过我们的处理,在evaluate()函数内部会被当成key去我们的集合中查找,若有,则返回key对应的value;若没有,直接返回数字字符串.主函数是一个简单的测试,别忘了,提交到Hive里运行的时候要把main函数注释掉.
business_no.properties
配置文件即为我们替换的字典文件,格式就是每一行key=value这种格式,部分内容如下:
1 | 0=北京 |
根据你的需要,你可以换成任何值.
pom文件
开发UDF函数,还需要一些关键的包,这里我们采用Maven来管理我们的依赖
1 | <project xmlns="http://maven.apache.org/POM/4.0.0" |
打包jar包
在main函数里调试没问题之后,就可以把main函数注释掉,打包成jar包.打包有很多方法,用IDEA自带的工具就可以打包,具体方法如下:
File-->Project StructureArtifacts,点中间绿色的+:-->JAR-->From modules with dependenciesName:里填你希望生成的名字,例如BusinessType:jar- 输出路径默认就行,不用改.然后一定要勾选上
Build on make - 依赖的jar包这里可以不用,Hive,Hadoop里都有,除非有其他包你需要加入,全选上,点
-号都去掉
回到IDEA主界面,Build-->Make Project.在输出路径就可以找到jar包了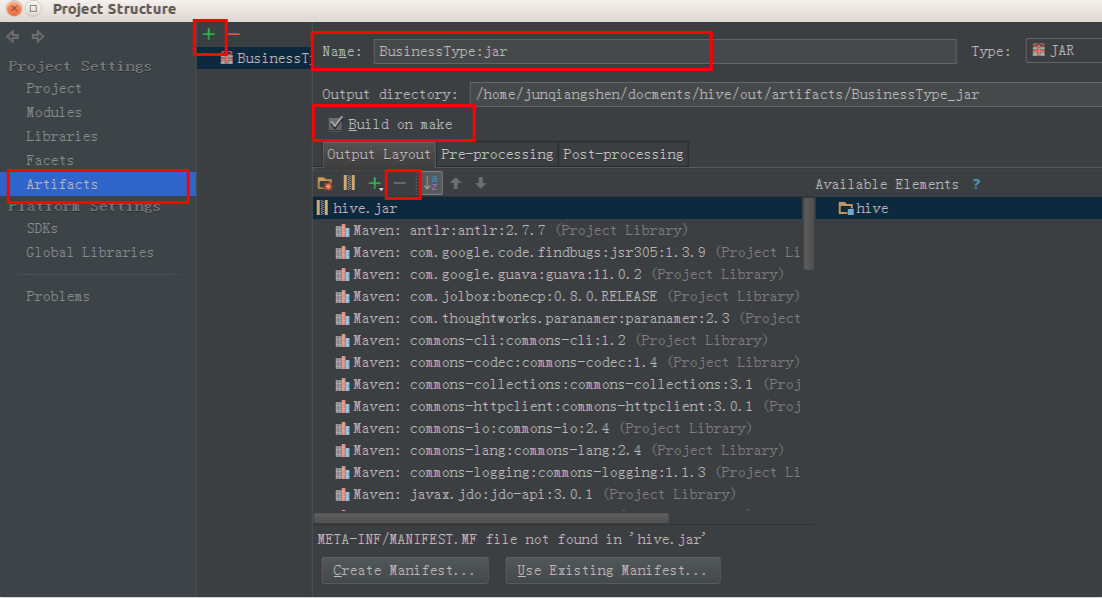
还有个打包比较简单的,直接用jar命令,以本程序为例
1 | cd target/classes |
目录结构如上所示,打包命令为:
1 | jar cvf BusinessType.jar . |
注意:.表示打包当前目录下所有文件,包括子目录,BusinessType.jar是生成的jar包名.
部署到Hive上使用
写了个UDF,最后怎么在Hive里用呢?介绍两种方法,一种是临时使用.
临时方案
如果只是想测试一下,可以使用临时方案,简单方便,只是每次启动Hive客户端之前都要添加,创建函数,退出Hive客户端函数就会自动销毁了.
假设jar包存放在服务器上的/home/tmp/目录下:
- 添加jar包
1 | hive> add jar /home/tmp/BusinessType.jar; |
- 创建临时函数
1 | hive> create temporary function business_type_func as 'UDF.BusinessType'; |
**注意:**切记,如果你的类有包名,要添加完整路径,例如我的类在UDF包里面,所以在创建函数的时候天的路径为UDF.BusinessType.
- 建一张dual表测试
dual表的概念来自oracle,数据库建立时即与数据字典一起初始化,该表只有一个varchar2类型名为dummy的字段,表数据只有一行“X”,用来查询一些系统信息,如:
1 | select sysdate from dual; |
为了能在hive中测试一些时间、数学、聚合函数,可以仿照oracle创建dual表。
1 | hive> create dual (dummy String); |
- 测试函数
我们新建的临时函数名为business_type_func,可以这么测试
1 | hive> select business_type_func(1) from dual; |
持久方案
每次都要执行这个命令,如果确实是需要用的,不用每次都这么麻烦.还有一个原因,我写的这个函数不知道为什么,每次运行都会出问题,但是数据明明都可以跑出来,后来我就采用了下面的方法,就可以了.
我们可以把我们开发的jar包拷贝到Hive的lib目录下,然后如果这个目录在环境变量里,就可以每次启动的时候加载
1 | # 拷贝jar包到hive的lib目录 |
在文件中添加下面两行内容:
1 | add jar /home/hive/hive-0.12.0/lib/BusinessType.jar; |
然后重启就可以了,也不用再创建函数了,这个函数就在Hive启动时就会一起加载到Hive内部.
后记: 如果你也出现了
1 | ERROR 1148 (42000) at line 1: The used command is not allowed with this MySQL version |
可以尝试采用第二种部署方式,至于原因还不明,有时间再研究.