用Vim对比两个文件的不同
从mysql数据库抽取数据到hadoop时,中间加了一个校验层,发现某天的数据Hive表里的和mysql里的差了一条,查询结果有7万多条,但是就只有一条不一样,最开始的思路是利用sql里的集合做差,即左外连接来过滤出那一条记录,但是由于Hive里是分区数据,查询语句怎么写都不对,后来换了一种思路,将查询结果保存到文件中,然后比较两个文件的不同来判断差了哪一条数据.
具体步骤
- Hive数据导出到文件
利用到了管道,将结果输入到文件,具体命令为:
1 | sudo -uuser_name /home/dev/hive-0.12.0/bin/hive -database dw_subject -e "select idid,create_time from table_name where (create_time>='2015-10-29 00:00:00' and create_time<='2015-10-29 23:59:59') order by idid;" > subject.txt |
注意,最好按照主键来将结果进行排序,因为数据很多,时间也可能有重复的,如果按时间来排序,时间相同的数可能顺序会有差异,7万多数据对比起来还是很麻烦的,所以尽量选不重复的字段排序,反正,最好能够保证排序不存在二义性即可.
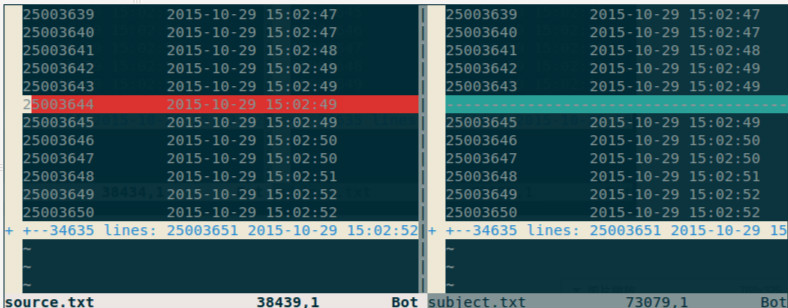
- 利用vim比较两个文件
假设这两个文件是subject.txt和source.txt,命令如下:
1 | sudo vim -d source.txt subject.txt |
最终的效果如下图所示: